品牌型号:联想拯救者R7000
系统:Windows 10专业版
软件版本:Anaconda 3
Anaconda非常适合用于数据分析工作,因为Anaconda集成了很多数据分析工具和库,使得数据分析师能够非常方便地进行数据处理和建模。对于初学者来说,使用Anaconda可以减少配置上的麻烦。接下来,本文将介绍如何使用Anaconda进行数据分析,以及Anaconda数据集放哪的问题,帮助你更好地使用Anaconda进行数据分析。
一、Anaconda进行数据分析
Anaconda集成了Python的数百个开源包,并提供了Jupyter Notebook和Spyder集成开发环境。Anaconda的最大优势在于,它为用户提供了一个完整的生态系统,使数据分析过程更加高效和便捷。以下是使用Anaconda进行数据分析的基本步骤:
1、安装Anaconda
首先,你需要下载并安装Anaconda。安装过程非常简单,安装完成后,Anaconda自带Python环境和常用的科学计算库,包括NumPy、Pandas、Matplotlib、Scikit-learn等,几乎覆盖了所有数据分析常用的库。
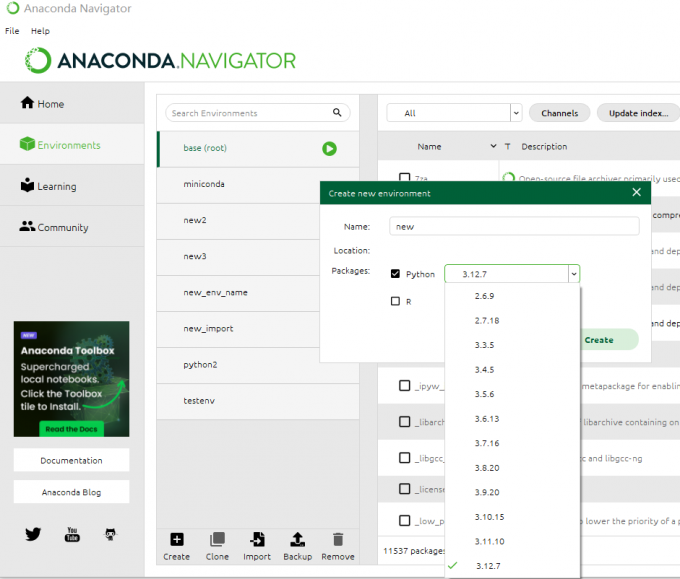
2、创建虚拟环境
Anaconda提供了环境管理功能,可以创建不同的Python环境。对于数据分析师来说非常重要,因为不同项目可能需要不同的Python版本和依赖包。你可以使用Anaconda Navigator创建虚拟环境。
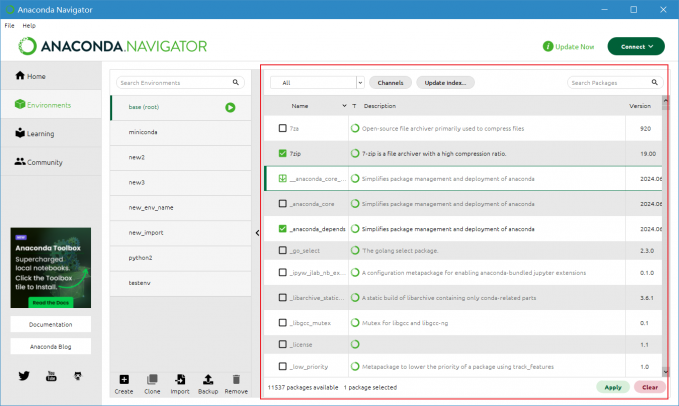
3、安装必要的库
在Anaconda Navigator切换到指定环境,并在右侧搜索安装需要使用的包,勾选后点击Apply下载安装。
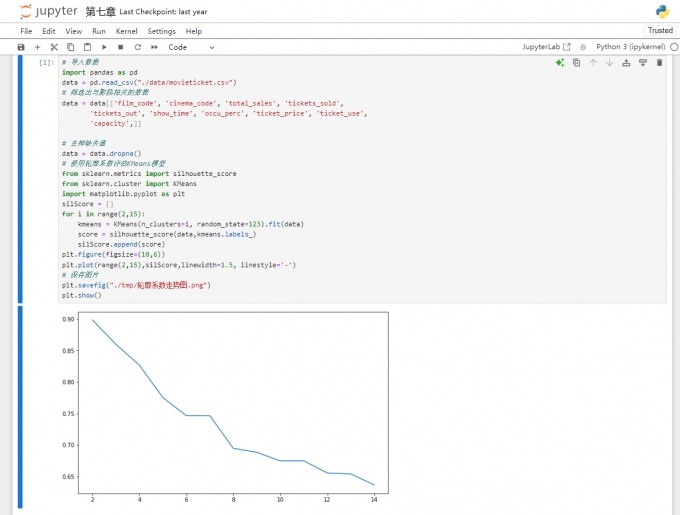
4、启动Jupyter Notebook进行数据分析
Anaconda内置了Jupyter Notebook,这是一个被广泛使用的交互式数据分析工具。你可以在开始菜单或者使用命令“jupyter notebook”启动Jupyter Notebook。

启动后,在浏览器中新建Notebook,编写代码并实时运行,你可以使用Scikit-learn来构建和评估机器学习模型。Scikit-learn内置了许多常用的算法,如线性回归、决策树、支持向量机等,足以满足大多数数据分析需求。
二、Anaconda数据集放哪
在进行数据分析时,处理数据集是非常重要的。在Anaconda环境中,数据集应该放在哪个位置呢?在实际开发中,Anaconda并没有特定的数据存储位置,以下是几种常见的选择:
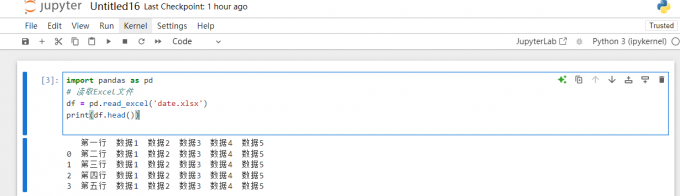
1、与Jupyter Notebook文件同目录
你可以将数据集文件(如CSV或Excel文件)与Notebook文件放在同一个目录下。这样,在Notebook中读取数据集时,只需使用相对路径即可。例如:
import pandas as pd
# 读取Excel文件
df = pd.read_excel('date.xlsx')
print(df.head())
这样可以确保代码的可移植性,因为文件路径相对简洁,便于项目在不同环境之间的迁移。
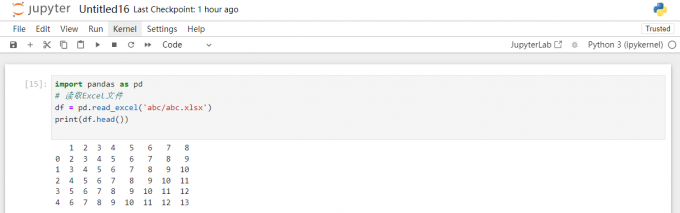
2、使用指定的数据目录
如果你有多个数据集,或者数据集较大,可以创建一个专门用于存放数据的文件夹。假设你将所有的数据文件放在项目目录下的“ABC”文件夹中:
data = pd.read_csv('abc/abc.csv')
三、总结
以上就是Anaconda如何进行数据分析,Anaconda数据集放哪的相关内容。对数据分析师来说,Anaconda是一个不可缺少的工具,它不仅简化了环境配置和库管理的工作,还为数据分析工作提供了强大的支持。有了Anaconda,你可以创建虚拟环境、安装必要的库、使用Jupyter Notebook进行构建机器学习模型。关于数据集的存放位置,Anaconda没有严格的要求,可以根据需要将数据集放在文件夹中,希望本文对你有所帮助。
署名:Hungry
